



没有遇到故障的运维不是合格的运维,没有处理故障的运维不是好运维。
做运维这么多年,每天依然提心吊胆,担心突发故障,打破生活节奏。
可是,人算不如天算,**大部分故障都来源于近乎合理的操作**,这次也是一样。
起因是要把几百G的数据传输到阿里云的Nas,通过外网挂载的方式拷贝。按道理讲这没什么问题,不就几百G的数据么,之前拷贝几个T的数据都没问题。
可偏偏不按道理讲。
这几百G的数据全是由大量的小文件组成,在拷贝的时候既要频繁的占用本地磁盘IO,也要占用网络IO,然后事情就发生了——服务器的负载直接干爆(原本8核的CPU,负载高达500多),而且服务器是老年机,配置很Low。这就导致该服务器直接处于死亡状态,更可气的是该服务器是K8S集群的master,Master宕机,其他节点失联,集群处于崩溃中。
负载下不来,服务器无法操作。只有出绝招了——重启服务器。
在提心吊胆中服务器终于是起来了。但是,新问题来了,Docker起不来,提示/var/lib/docker/overlays Input/Output error。
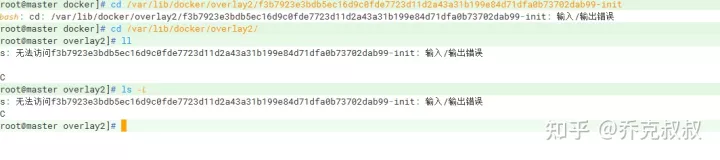
这特么不是尽给我惹事么,所幸的是只是这个目录下的部分文件异常,整个文件系统并没有损坏。
既然你起不来,那我就换一个目录吧,我就在/etc/docker/daemon.json中重新更改了目录:
cat > /etc/docker/daemon.json << EOF
{
"data-root": "/data/docker"
}
EOF
Docker起来了,看似向好的方向发展了,可是Docker压根用不了。

陷入了沉默,内心焦躁不安,如果不及时解决会影响整体的项目进度......
开始做最坏的打算——重做。随机开始把未备份的数据进行备份 ,然后另一方面问谷歌大佬,看有没有类似的问题,最后什么也没找到。
沉入谷底,如果重做,我一晚上都不一定能做好,但是不重做,所有的工作都可能停滞。
为了静下心,买了一盒泡面.....
其实问题的目标很明确了,修复好docker,一切都迎刃而解。
又重头去梳理Docker的配置。发现Docker的启动文件中有引入其他配置。

然后发现在docker-options.conf中有配置Docker的data-root,我就把其改了,把原来/etc/docker/daemon.json删了。

神奇的事情发生,Docker能够正常启动,也没有再报任何错误。
现在就开始启动Etcd,为了保险起见,将原有的数据进行了备份,然后重新恢复故障前最近的Etcd备份文件。
Etcd顺利起来了,然后apiserver、controller-manager等都起来了,整个集群开始正常运转。
**问题发生的出乎意料,问题解决的也出乎意料。**
所以,平时在工作中:
1、做好备份
2、谨慎操作
3、冷静分析
问题发生,总要找解决办法,做好最坏的打算。在解决问题的过程中一定要冷静,我有一阵子很急躁,导致没有仔细去看配置,所以延缓了恢复时间。
评论区