



作者 | 运维研习社
来源 | 运维研习社
地址 | https://mp.weixin.qq.com/s/hNntqwwq87dpWKeRyaKZfw
前言
由于 Redis 主从无法达到高可用性,所以 Redis 通过哨兵的方式在 Redis 主从基础上实现高可用 Redis 集群
Redis哨兵
哨兵是 redis 集群架构中非常重要的组件,哨兵主要用来解决主从复制故障时需要人为干预的问题。
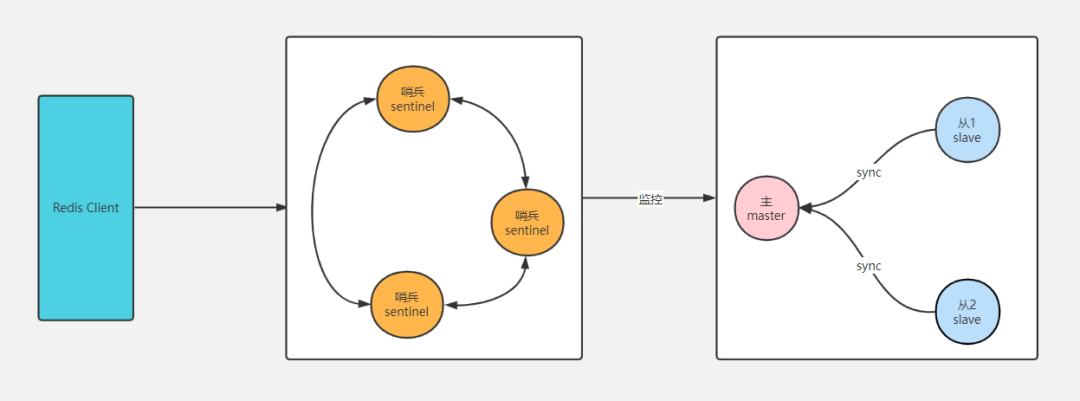
Redis 哨兵主要功能
-
集群监控:负责监控 Redis master 和 slave 是否正常工作
-
消息通知:redis实例故障,哨兵负责发送消息作为告警通知管理员
-
故障转移:master节点故障,自动重新选举master,实现集群自愈
-
配置中心:故障发生后,通知client客户端及其他slave新的master地址
原理
Redis哨兵使用的算法核心是Raft算法,主要用途就是用于分布式系统,系统容错,以及leader选举,整个过程如下:
- 每个 Sentinel 会自动发现其他 Sentinel 和从服务器,通过每秒一次的频率向它所知的主服务器、从服务器以及其他Sentinel实例发送一个PING命令
- 如果一个实例距离最后一次有效回复PING命令的时间超过 down-after-millisenconds 选项指定的值,那么这个实例会被 Sentinel 标记为主观下线,有效回复不一定是 PONG,可以是-LOADING或者-MASTERDOWN
- 如果一个主实例被标记为主管下线,那么正在监视这个主服务器的所有Sentinel要以每秒一次的频率去确认主实例确实进入了主管下线状态
- 如果一个主实例被标记为主观下线,并且超过quorum数量的Sentinel在指定的时间范围内认同这一判断,那么这个主实例就被标记为客观下线
- 在一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有主实例和从实例发送INFO命令,当一个主实例被Sentinel标记为客观下线时,Sentinel向下线主实例的所有从服务器发送INFO命令频率会从10秒改为每秒一次
- 当没有足够quorum数量的Sentinel同意主实例已经下线,主实例的客观下线状态就会被移除,当主服务器重新向Sentinel的PING命令返回有效回复时,主实例的主观状态会被移除
后面通过实例日志可以看到更详细的步骤。
哨兵搭建实践
主从搭建请参考上一篇,直接看哨兵配置,哨兵配置文件为sentinel.conf,配置参数详解如下:
# 哨兵sentinel实例运行的端口,默认26379
port 26379
# 哨兵sentinel的工作目录
dir ./
# 是否开启保护模式,默认开启。
protected-mode:no
# 是否设置为后台启动。
daemonize:yes
# 哨兵sentinel的日志文件
logfile:./sentinel.log
# 哨兵sentinel监控的redis主节点的
## ip:主机ip地址
## port:哨兵端口号
## master-name:可以自己命名的主节点名字(只能由字母A-z、数字0-9 、这三个字符".-_"组成。)
## quorum:当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
## 这里IP不要用127.0.0.1
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass,所有连接Redis实例的客户端都要提供密码。这里提示下,Redis,master实例也需要配置masteruth,否则master实例下线重新上线后,会无法加入到集群中
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
# 指定主节点应答哨兵sentinel的最大时间间隔,超过这个时间,哨兵主观上认为主节点下线,默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 指定了在发生failover主备切换时,最多可以有多少个slave同时对新的master进行同步。这个数字越小,完成failover所需的时间就越长;反之,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为1,来保证每次只有一个slave,处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间failover-timeout,默认三分钟,可以用在以下这些方面:
## 1. 同一个sentinel对同一个master两次failover之间的间隔时间。
## 2. 当一个slave从一个错误的master那里同步数据时开始,直到slave被纠正为从正确的master那里同步数据时结束。
## 3. 当想要取消一个正在进行的failover时所需要的时间。
## 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来同步数据了
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# 当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本。一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
# 对于脚本的运行结果有以下规则:
## 1. 若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10。
## 2. 若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
## 3. 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
配置好Sentinel配置之后,启动顺序是先启动Redis主,然后启动Redis从,主从启动完后,启动Sentinel。
启动完成后,登录进入Redis主实例,查看replication信息。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.22.29.101,port=6379,state=online,offset=4448,lag=1
slave1:ip=172.22.29.100,port=6379,state=online,offset=4448,lag=1
master_failover_state:no-failover
master_replid:e6627addc08ba16bf2be9ca484d5c9df387dd3d6
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:4448
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4448
然后进入 sentinel,查看 sentinel 信息。
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.22.29.99:6379,slaves=2,sentinels=3
# 两slave、三sentinel
查看哨兵日志.
11526:X 12 Feb 2022 16:18:36.615 # Sentinel ID is 6ed25761f58a921370b172db21c9912268eee355
11526:X 12 Feb 2022 16:18:36.615 # +monitor master mymaster 172.22.29.99 6379 quorum 2
11526:X 12 Feb 2022 16:18:36.616 * +slave slave 172.22.29.101:6379 172.22.29.101 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:18:36.620 * +slave slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:18:45.394 * +sentinel sentinel e0cc602d71cd7f9c0e68dbf799596c8f6a292af3 172.22.29.100 26379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:18:52.387 * +sentinel sentinel ba877d31906400bb1f3f631de248d5eaa78215d7 172.22.29.101 26379 @ mymaster 172.22.29.99 6379
此时哨兵配置文件已经被更新,查看哨兵配置最后.
# Generated by CONFIG REWRITE
protected-mode no
supervised systemd
user default on nopass ~* &* +@all
sentinel myid e0cc602d71cd7f9c0e68dbf799596c8f6a292af3
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel current-epoch 0
sentinel known-replica mymaster 172.22.29.100 6379
sentinel known-replica mymaster 172.22.29.101 6379
sentinel known-sentinel mymaster 172.22.29.101 26379 ba877d31906400bb1f3f631de248d5eaa78215d7
sentinel known-sentinel mymaster 172.22.29.99 26379 6ed25761f58a921370b172db21c9912268eee355
模拟故障迁移
关闭master的redis。
systemctl stop redis
查看哨兵日志
# 哨兵1
11526:X 12 Feb 2022 16:31:13.177 # +sdown master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.267 # +odown master mymaster 172.22.29.99 6379 #quorum 3/2
11526:X 12 Feb 2022 16:31:13.267 # +new-epoch 1
11526:X 12 Feb 2022 16:31:13.267 # +try-failover master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.270 # +vote-for-leader 6ed25761f58a921370b172db21c9912268eee355 1
11526:X 12 Feb 2022 16:31:13.272 # ba877d31906400bb1f3f631de248d5eaa78215d7 voted for ba877d31906400bb1f3f631de248d5eaa78215d7 1
11526:X 12 Feb 2022 16:31:13.277 # e0cc602d71cd7f9c0e68dbf799596c8f6a292af3 voted for 6ed25761f58a921370b172db21c9912268eee355 1
11526:X 12 Feb 2022 16:31:13.329 # +elected-leader master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.330 # +failover-state-select-slave master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.385 # +selected-slave slave 172.22.29.101:6379 172.22.29.101 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.385 * +failover-state-send-slaveof-noone slave 172.22.29.101:6379 172.22.29.101 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.468 * +failover-state-wait-promotion slave 172.22.29.101:6379 172.22.29.101 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.700 # +promoted-slave slave 172.22.29.101:6379 172.22.29.101 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.700 # +failover-state-reconf-slaves master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:13.752 * +slave-reconf-sent slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:14.330 # -odown master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:14.715 * +slave-reconf-inprog slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:14.715 * +slave-reconf-done slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:14.770 # +failover-end master mymaster 172.22.29.99 6379
11526:X 12 Feb 2022 16:31:14.770 # +switch-master mymaster 172.22.29.99 6379 172.22.29.101 6379
11526:X 12 Feb 2022 16:31:14.770 * +slave slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.101 6379
11526:X 12 Feb 2022 16:31:14.770 * +slave slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
11526:X 12 Feb 2022 16:31:44.772 # +sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
# 哨兵2
1809:X 12 Feb 2022 16:31:13.150 # +sdown master mymaster 172.22.29.99 6379
1809:X 12 Feb 2022 16:31:13.274 # +new-epoch 1
1809:X 12 Feb 2022 16:31:13.277 # +vote-for-leader 6ed25761f58a921370b172db21c9912268eee355 1
1809:X 12 Feb 2022 16:31:13.752 # +config-update-from sentinel 6ed25761f58a921370b172db21c9912268eee355 172.22.29.99 26379 @ mymaster 172.22.29.99 6379
1809:X 12 Feb 2022 16:31:13.752 # +switch-master mymaster 172.22.29.99 6379 172.22.29.101 6379
1809:X 12 Feb 2022 16:31:13.753 * +slave slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.101 6379
1809:X 12 Feb 2022 16:31:13.753 * +slave slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
1809:X 12 Feb 2022 16:31:43.792 # +sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
# 哨兵3
11511:X 12 Feb 2022 16:31:13.167 # +sdown master mymaster 172.22.29.99 6379
11511:X 12 Feb 2022 16:31:13.268 # +odown master mymaster 172.22.29.99 6379 #quorum 2/2
11511:X 12 Feb 2022 16:31:13.268 # +new-epoch 1
11511:X 12 Feb 2022 16:31:13.268 # +try-failover master mymaster 172.22.29.99 6379
11511:X 12 Feb 2022 16:31:13.271 # +vote-for-leader ba877d31906400bb1f3f631de248d5eaa78215d7 1
11511:X 12 Feb 2022 16:31:13.272 # 6ed25761f58a921370b172db21c9912268eee355 voted for 6ed25761f58a921370b172db21c9912268eee355 1
11511:X 12 Feb 2022 16:31:13.277 # e0cc602d71cd7f9c0e68dbf799596c8f6a292af3 voted for 6ed25761f58a921370b172db21c9912268eee355 1
11511:X 12 Feb 2022 16:31:13.752 # +config-update-from sentinel 6ed25761f58a921370b172db21c9912268eee355 172.22.29.99 26379 @ mymaster 172.22.29.99 6379
11511:X 12 Feb 2022 16:31:13.752 # +switch-master mymaster 172.22.29.99 6379 172.22.29.101 6379
11511:X 12 Feb 2022 16:31:13.753 * +slave slave 172.22.29.100:6379 172.22.29.100 6379 @ mymaster 172.22.29.101 6379
11511:X 12 Feb 2022 16:31:13.753 * +slave slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
11511:X 12 Feb 2022 16:31:43.763 # +sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
可以看到,master从+sdown,到+odown,之后重新进行leader选举,并切换master为slave2.
模拟节点恢复
启动刚才的redis节点.
systemctl start redis
查看哨兵日志.
# 哨兵1
11526:X 12 Feb 2022 16:38:49.705 # -sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
11526:X 12 Feb 2022 16:38:59.646 * +convert-to-slave slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
# 哨兵2
1809:X 12 Feb 2022 16:38:50.513 # -sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
# 哨兵3
11511:X 12 Feb 2022 16:38:49.954 # -sdown slave 172.22.29.99:6379 172.22.29.99 6379 @ mymaster 172.22.29.101 6379
查看redis日志.
11496:M 12 Feb 2022 16:38:59.651 * Replica 172.22.29.99:6379 asks for synchronization
11496:M 12 Feb 2022 16:38:59.651 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'a55b8b82d079247bb8b0facd5a9d5562ac91362d', my replication IDs are '0d45dd66cf94887da5567c772391695e2c8c6b82' and 'e6627addc08ba16bf2be9ca484d5c9df387dd3d6')
11496:M 12 Feb 2022 16:38:59.651 * Starting BGSAVE for SYNC with target: disk
11496:M 12 Feb 2022 16:38:59.652 * Background saving started by pid 11529
11529:C 12 Feb 2022 16:38:59.654 * DB saved on disk
11529:C 12 Feb 2022 16:38:59.655 * RDB: 2 MB of memory used by copy-on-write
11496:M 12 Feb 2022 16:38:59.705 * Background saving terminated with success
11496:M 12 Feb 2022 16:38:59.705 * Synchronization with replica 172.22.29.99:6379 succeeded
此时节点重新加入集群.
关于Sentinel节点的计算
Sentinel节点计算主要关注两个参数:
- quorum: 是确认odown的最少的哨兵数量
- majority: 授权进行主从切换的最少的哨兵数量
主从的切换与这俩有关,每次一个哨兵要做主从切换,首先需要quorum数量的哨兵认为odown,然后选举出一个哨兵来做切换,这个哨兵还得得到majority哨兵的授权,才能正式切换。
如果quorum < majority,比如5个哨兵,majority就是3,quorum设置为2,那么就3个哨兵授权就可以执行切换,但是如果quorum >= majority,那么必须quorum数量的哨兵进行授权,比如5个哨兵,quorum是5,那么必须5个哨兵都同意授权,才能执行切换。
majority计算:
int sentinelIsQuorumReachable(sentinelRedisInstance *master, int *usableptr) {
dictIterator *di;
dictEntry *de;
int usable = 1; /* Number of usable Sentinels. Init to 1 to count myself. */
int result = SENTINEL_ISQR_OK;
int voters = dictSize(master->sentinels)+1; /* Known Sentinels + myself. */
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
usable++;
}
dictReleaseIterator(di);
if (usable < (int)master->quorum) result |= SENTINEL_ISQR_NOQUORUM;
if (usable < voters/2+1) result |= SENTINEL_ISQR_NOAUTH;
if (usableptr) *usableptr = usable;
return result;
}
majority=voters/2+1
为什么哨兵至少3个节点
如果哨兵集群仅仅部署了个2个哨兵实例,那么它的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),如果其中一个哨兵宕机了,就无法满足majority>=2这个条件,那么在master发生故障的时候也就无法进行主从切换。
关于脑裂
redis的集群脑裂是指因为网络问题,导致redis master节点跟redis slave节点和sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。此时存在两个不同的master节点,就像一个大脑分裂成了两个。集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
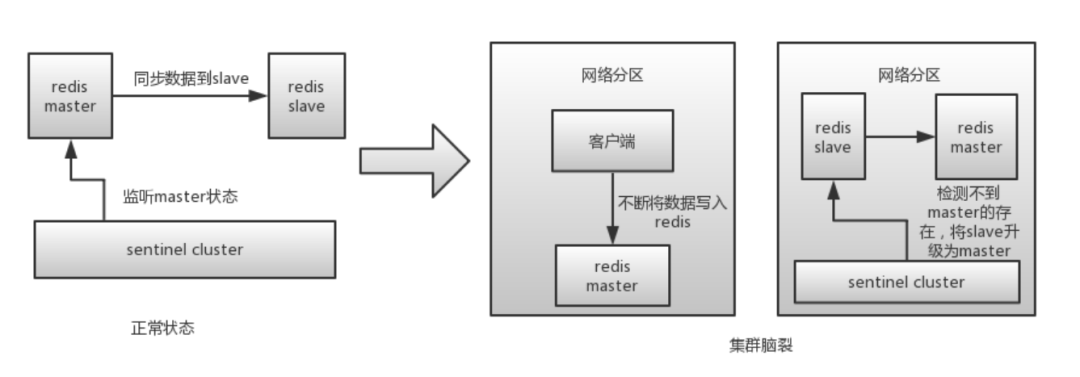
解决脑裂与两个参数有关:
- min-replicas-to-write 3
- min-replicas-max-lag 10
第一个参数表示连接到master的最少slave数量 第二个参数表示slave连接到master的最大延迟时间。
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
总结
Redis 哨兵的作用就是解决 Redis 高可用,而为了提高 Redis 的吞吐量,Redis 提供了Cluster集群解决方案。
评论区